Learning Visual Context by Comparison
TL;DR
The paper Learning Visual Context by Comparison describes the “attend-and-compare” module, a light-weight attention mechanism that can be added on to ResNet-style computer vision models. It was published by folks from Lunit on arXiv in July 2020 and was a conference paper at ECCV 2020.

Since Lunit is now the parent company of my present employer, I thought it would be nice to find out something about their cool ideas. First, let’s meet the authors.
Authors
- Minchul Kim (김민철) - (Lunit: 2018-2021), now at Google.
- Jongchan Park (박종찬) - (Staff Research Scientist at Lunit: 2018–current), organized Multi-Modal Foundation Models for Cancer Detection and Prevention.
- Seil Na (나세일) - (Research Scientist, Lunit 2019-current)
- Chang Min Park (박창민) - Radiology, Seoul National University Hospital
- Donggeun Yoo (유동근) - (Co-founder & Chief of Research at Lunit)
Several founders and early Lunitians were lab-mates in a group run by In So Kweon at Korea Advanced Institute of Science and Technology (KAIST) in Daejeon, South Korea. KAIST is a public research university founded in 1971, known as the “MIT of South Korea”. This paper builds on CBAM: Convolutional Block Attention Module (2018) from that lab.

Context
This paper came during a wave of exploration of variants of CNN architectures, especially variants incorporating an attention mechanism.
Timeline of Computer vision
- Backpropagation Applied to Handwritten Zip Code Recognition, Y. LeCun et al, 1989
- AlexNet, ImageNet Classification with Deep Convolutional Neural Networks, Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton, 2012
- Neural Machine Translation by Jointly Learning to Align and Translate, September 2014
- ResNet, December 2015
- YOLO (You Only Look Once), June 2015
- Attention Is All You Need, June 2017
- Vision transformers, October 2020
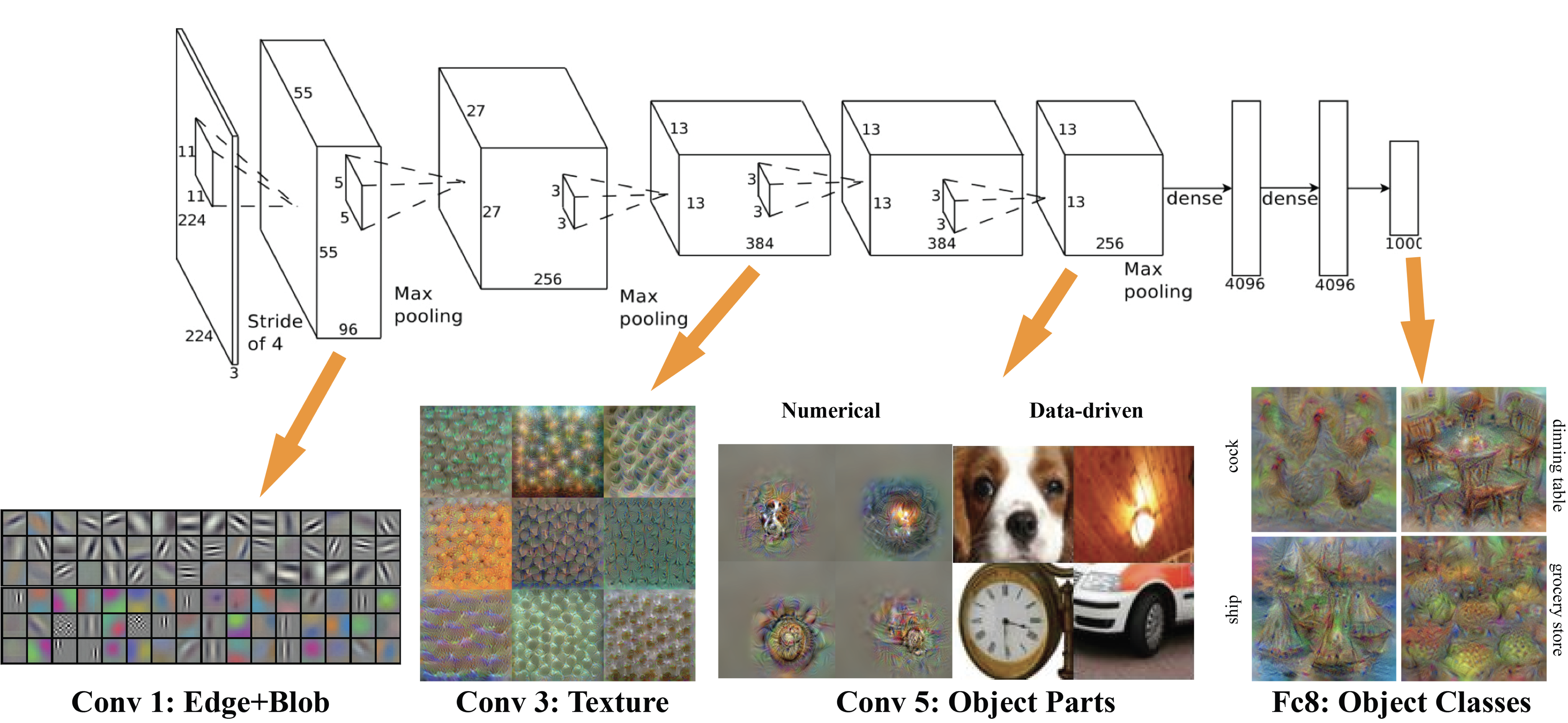
Convolutional Neural Networks
As background, recall that convolutional networks learn feature maps whose complexity increases with depth in the network.
Attend-and-compare method
Inspiration
“We paid attention to how radiology residents are trained, which led to the following question: why don’t we model the way radiologists read X-rays? When radiologists read chest X-rays, they compare zones, paying close attention to any asymmetry between left and right lungs, or any changes between semantically related regions, that are likely to be due to diseases.”
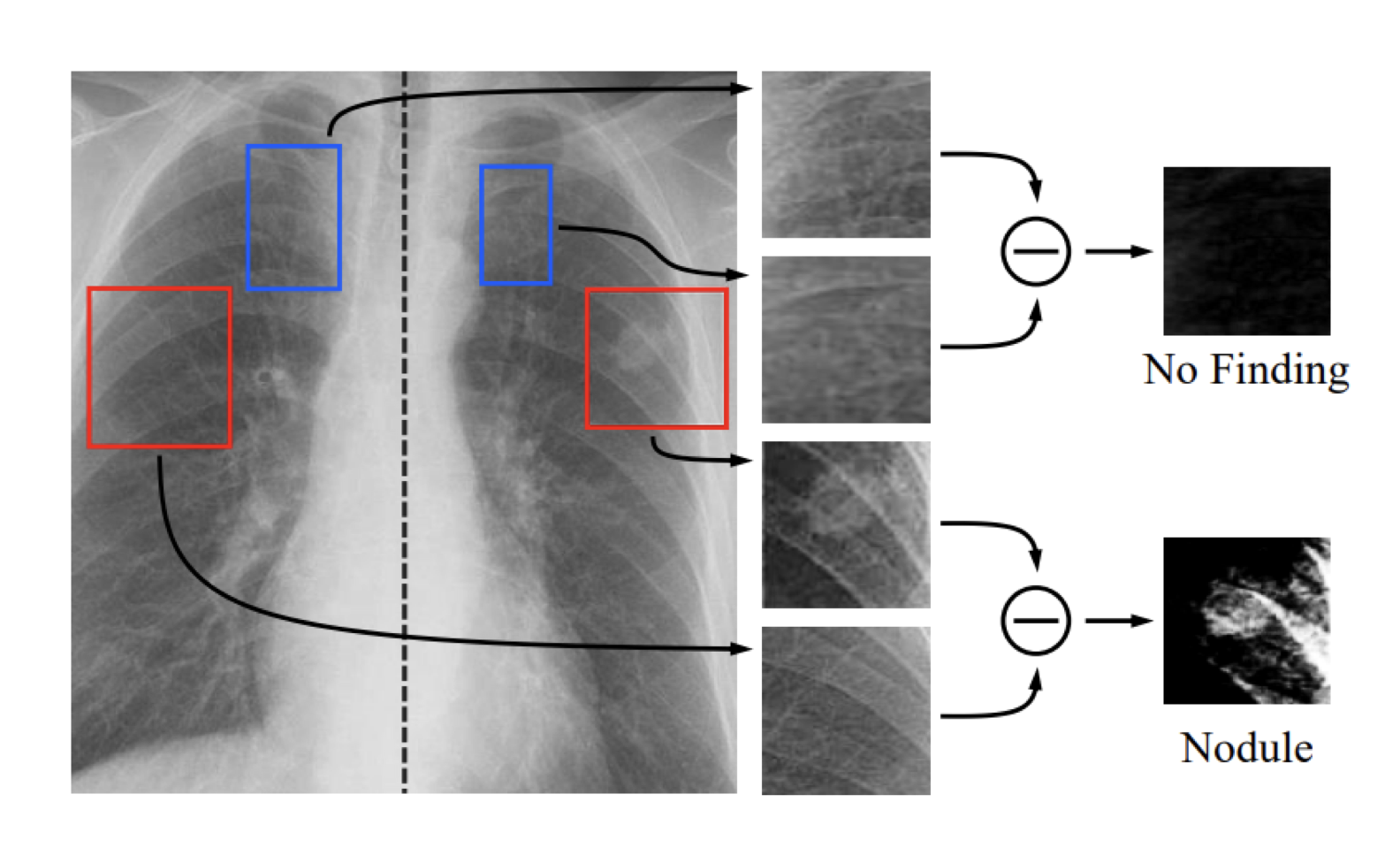
“In this paper, we present a novel module, called Attend-and-Compare Module (ACM), that extracts features of an object of interest and a corresponding context to explicitly compare them by subtraction, mimicking the way radiologists read X-rays.”
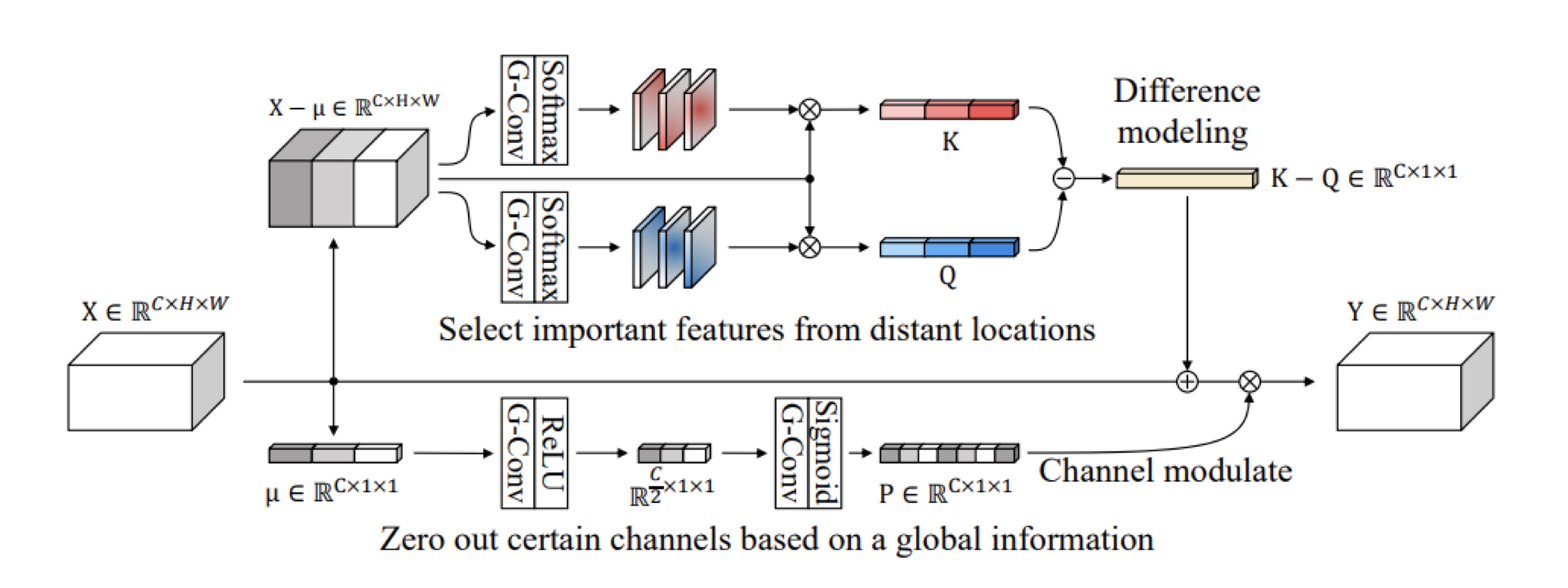
ACM derives a comparison signal from two attention-pooled prototypes, \(K-Q\). The squeeze-and-excitation gate (P) then reweights the channels of (X+(K-Q)).
Computing the ACM block
The ACM block computes K by projecting the feature map \(X\) with \(W_K\), which is a 1×1 convolution producing a single-channel score map. Then softmax over spatial locations \((i,j)\) to produce a \(C \times 1 \times 1\) vector. Q is computed similarly.
\[X \in \mathbb{R}^{C \times H \times W}\]This is equation (2) of the paper:
\[K = \sum_{i,j \in H,W} \frac{ \exp(W_K X_{i,j}) }{ \sum_{h,w} \exp(W_K X_{h,w}) } X_{i,j}\]I think \(K\) and \(Q\) are little easier to read like this:
\[K = \sum_{i,j} \operatorname{softmax}_{(i,j)\in H\times W}\!\big(W_K X\big)_{i,j}\, X_{i,j}\] \[Q = \sum_{i,j} \operatorname{softmax}_{(i,j)\in H\times W}\!\big(W_Q X\big)_{i,j}\, X_{i,j}\] \[K, Q \in \mathbb{R}^{C \times 1 \times 1}\]Subtracting \(K-Q\) highlights contrasting features. It might learn to compare left vs right lung, although specific comparisons are learned and not baked into the algorithm. The algorithm doesn’t enforce anatomical pairing (left-right symmetry) unless the data and training encourage it. To get the result of the ACM we add that difference between \(K\) and \(Q\) back to the feature map \(X\) and multiply by \(P\).
\[F_{acm}(X) = P(X + (K-Q))\]…where \(P\) is a squeeze-and-excitation block whose job it is to highlight features that are helpful for solving the task at hand.
\[P = \sigma \circ \text{conv}^{1\times1}_{2} \circ \text{ReLU} \circ \text{conv}^{1\times1}_{1}(\mu)\]CNNs with Attention
The late twenty-teens was a time of exploration of architectures combining attention and convolutions. A nice review paper that covers these kinds of methods is Visual attention methods in deep learning: An in-depth survey Hassanin, 2022 from which we get this figure:
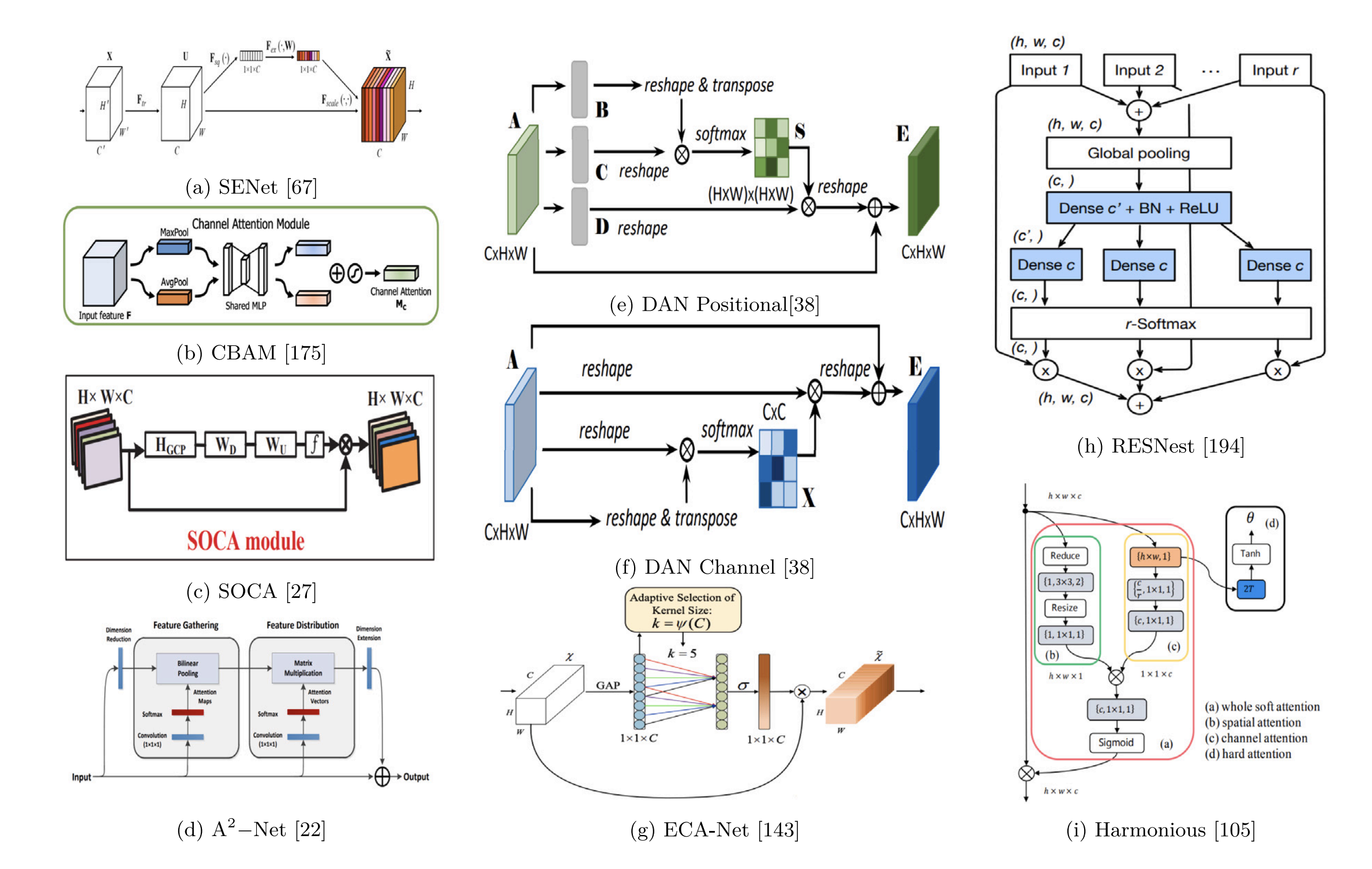
In the figure, (a) is the squeeze-and-excitation (SE) block. Convolutional Block Attention Module (CBAM), (b), is a channel-and-spatial attention module for learning to attend to informative regions. CBAM is prior work from the same lab at KAIST. In contrast to ACM’s spatial attention pooling, CBAM learns an explicit spatial gating mask \(M_s\in\mathbb{R}^{1\times H\times W}\) that is applied to the feature map.
Comparison with transformer-style self-attention
In transformers, K and Q are projections of individual tokens or image patches in vision transformers and they are used to compute pairwise attention. In ACM, K and Q are globally-pooled summaries of two contrasting regions which are subtracted to explicitly model comparison. This signal is then injected back to the feature map with the effect of highlighting difference.
\[Q = XW_Q,\quad K = XW_K,\quad V = XW_V\] \[\text{Attention}(Q, K, V) = \text{softmax}\!\left(\frac{QK^\top}{\sqrt{d}}\right)V\]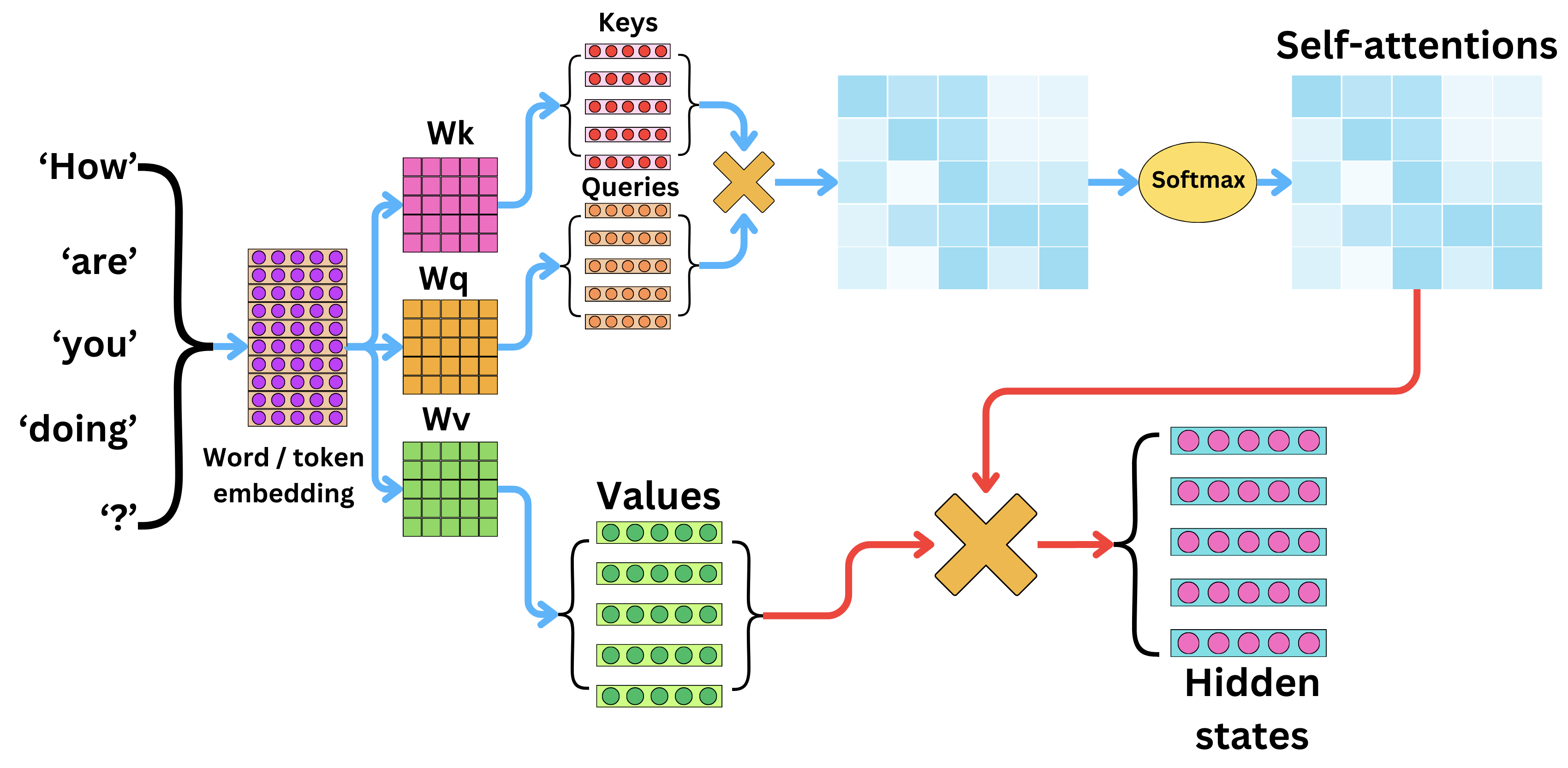
Transformer-style attention is quadratic \(N \times N\) in the number of input tokens, providing pairwise mixing of information. By pooling over the spatial dimensions, ACM is lighter with more like linear scaling. \(K\) and \(Q\) are two global attention poolings whose difference is beneficial to recognition tasks. By splitting channels into groups and learning separate attention maps for each group, ACM gains something in the same spirit as multiheaded attention.
Is it still worth knowing?
The attend-and-compare paper is from 2020 and sits in the “CNN plus attention” niche of the era before vision transformers. It’s a plug-in module for convolutional backbones that (a) learns where to look, and (b) adds channel reweighting. ACM makes explicit the inductive bias that comparison is important by encoding a difference signal and injecting it back into the feature map. ACM fits well with medical imaging tasks where compare-and-contrast is naturally informative.
The focus of research has largely moved on to vision transformers and more recently to multimodal foundation models. Modern deep learning practice improves performance by training or pretraining more general models on larger datasets. Architecture tweaks matter less than scale. Pragmatically, though, modern CNNs remain competitive with transformers especially where training data is scarce or expensive.