Collaboration Challenges in Building ML-Enabled Systems
Notes on: Collaboration Challenges in Building ML-Enabled Systems: Communication, Documentation, Engineering, and Process by Nadia Nahar, Shurui Zhou, Grace Lewis, and Christian Kästner.
Building ordinary software systems is hard enough. Introducing machine learning adds more ways for things to go sideways. The technical challenges certainly exist, but even more vexing are organizational snafus. So, it’s encouraging –not to mention validating, thank you– that researchers are studying common failure modes.
The paper synthesizes themes from practitioner interviews exploring how introducing machine learning into software projects challenges collaboration. A lot of the pitfalls sound really familiar. What follows are my takeaways.
Unicorns wanted
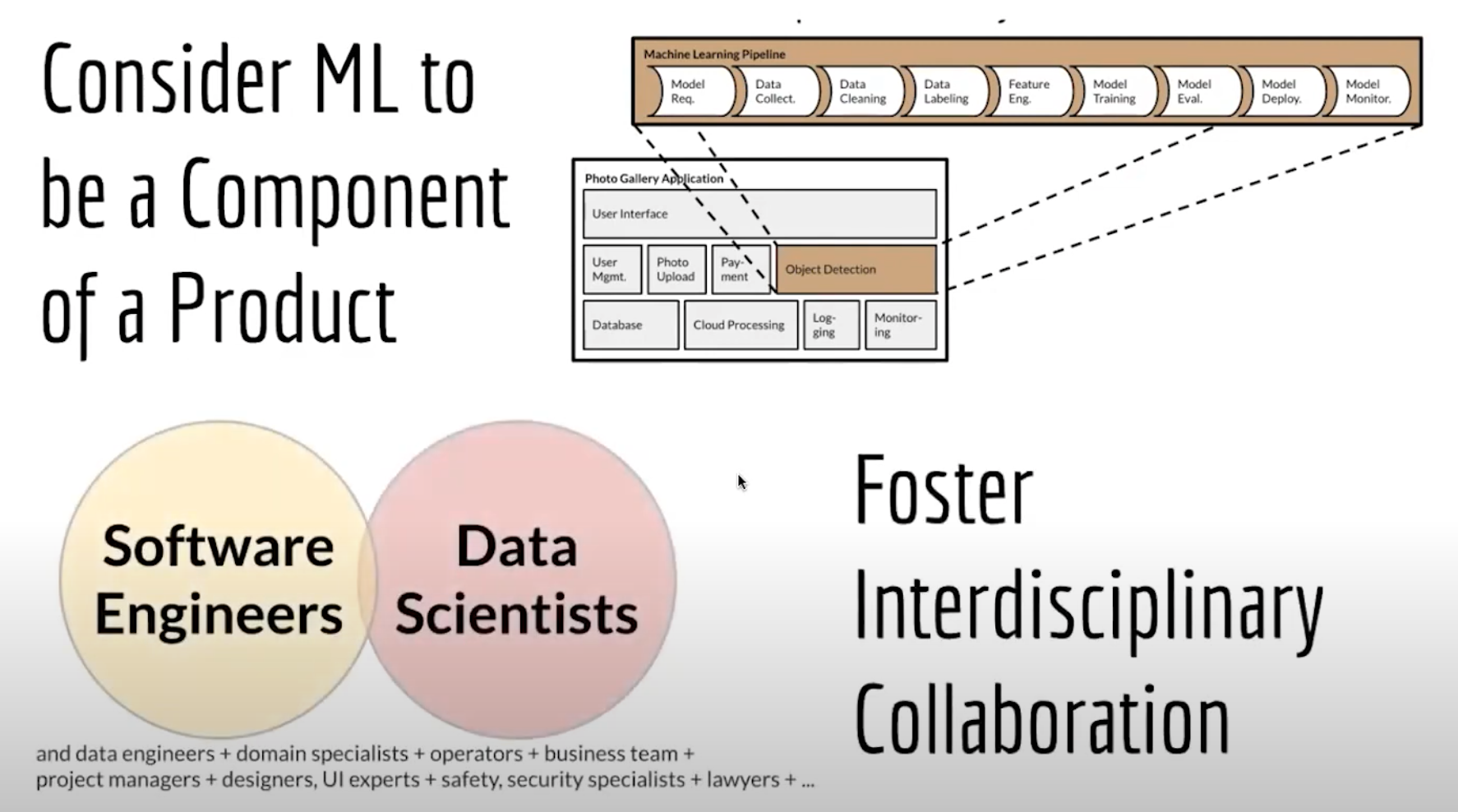
Even the most gullible believers in mythical creatures like unicorns or 10x engineers have to admit, at some point, that one person can’t do it all. Abstraction and a divide and conquer strategy are essential. Dividing software into components and hiding internals behind interfaces are key strategies of modular software development. The interface is where teams negotiate and renegotiate how to divide work and assign responsibilities.
Common Development Trajectories
Most ML containing products are built either model-first, building the model then building a product around it, or product-first, adding ML features to an existing product. Less commonly, model and product are developed in parallel.
Collaboration Points
Data scientists and software engineers are certainly not the first to realize that interdisciplinary collaborations are fraught with communication and cultural challenges. Here are the main points of friction that surfaced in the interviews.
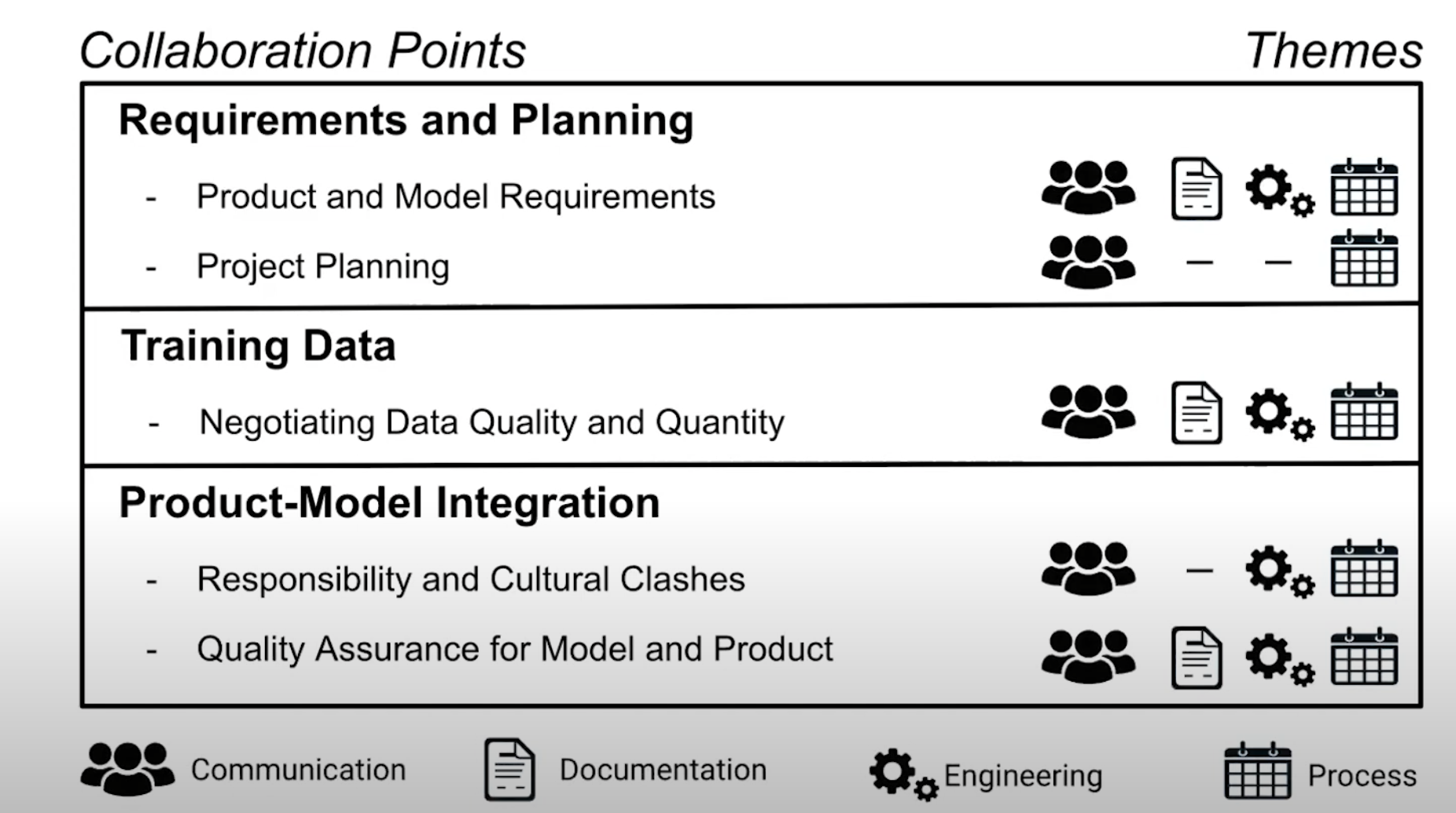
Requirements
Model requirements are often underspecified and should consider:
- accuracy
- training time
- inference time
- fairness
- explainability
- monitoring data and models in production
Model building is frequently a research project with uncertain timelines and results making planning and estimation even more fictional than usual.
Data
Amount and quality of data for training and retraining is a key determinate of the accuracy of the model. One frequent misunderstanding is failure to recognize the need for retraining with up-to-date training data.
Successful modeling requires understanding the context of a dataset. How data was collected and what biases and flaws does that introduce? How much data cleaning is needed and can we afford?
Power dynamics within the organization can make it hard for modeling teams to access data. (Can confirm.) Who has ownership of data? Who controls access? Are there security and privacy concerns? How will the modeling team know when data sources change format, semantics, or distribution?
Product / model integration
Many organizations seem to underestimate the engineering effort required to turn a model into a product. Introducing machine learning increases complexity which makes good engineering practices even more important.
- Testing systems that include ML models is tricky.
- Extending version control to data and models is desired but “elusive”.
- Model teams benefit from receiving feedback on their model from production systems, but monitoring in production is often neglected.
To build an ML-enabled system, both ML components and traditional non-ML components need to be integrated and deployed, requiring data scientists and software engineers to work together, typically across multiple teams. We found many conflicts at this collaboration point, stemming from unclear processes and responsibilities, as well as differing practices and expectations. Culture clashes between data science and software engineering are made worse by unclear responsibilities and boundaries.
Differing expectations regarding code quality, documentation, and version control can lead to conflict. Software engineers expressed frustration that data scientists do not follow the same practices or have the same quality standards.
Siloing data scientists is widely recognized as problematic, fostering integration problems. Some orgs, particularly big tech, expect engineering skills from all data science hires. But, data scientists often don’t want engineering or ops responsibilities, prefering instead to be supported by embedded engineering and ML Ops.
The product view
OK, we’ve seen what can go wrong. What works?
Keeping a product mindset helps. It’s quite helpful for all to remember that in the end a model is not particularly useful except as a component in a product.