Deep Learning - Sequence Models - Week 3
Notes on week 3 of the Sequence Models class, part of Andrew Ng’s deep learning series on Coursera.
A language model computes a probability distribution over sequences of words in a language. It assigns a probability of a given word following a sequence of words.
Encoder-decoder
A basic machine translation system can be designed in two stages - an encoder and a decoder.
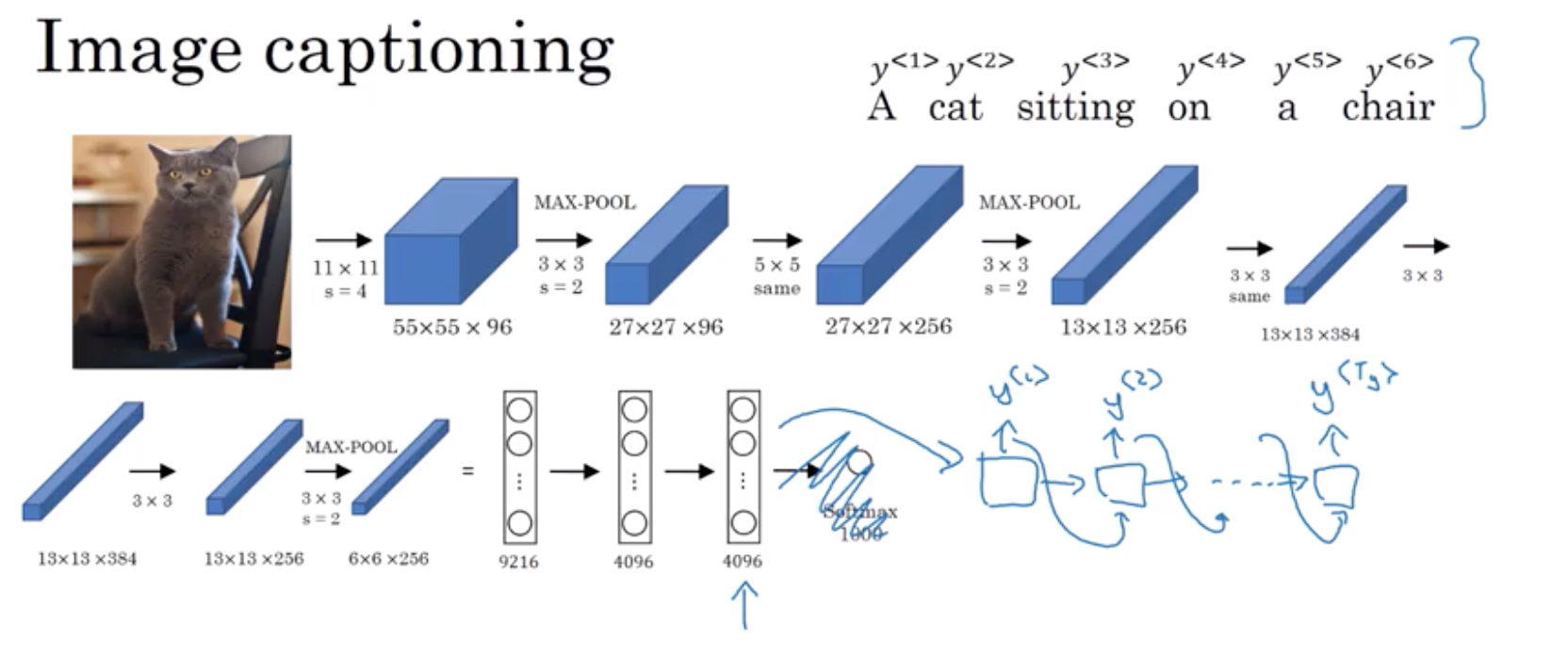
An encoder-decoder design can also be used for image captioning. In the diagram below, AlexNet is modified by chopping off the final softmax classifier, leaving a 4096-element vector that represents an encoding of the image. That encoding can then be fed to a decoder that models the probability of a phrase conditioned on the encoded image yielding the caption.
Attention
The encoder-decoder design has trouble with longer sentences. A highly successful alternative is the attention model.
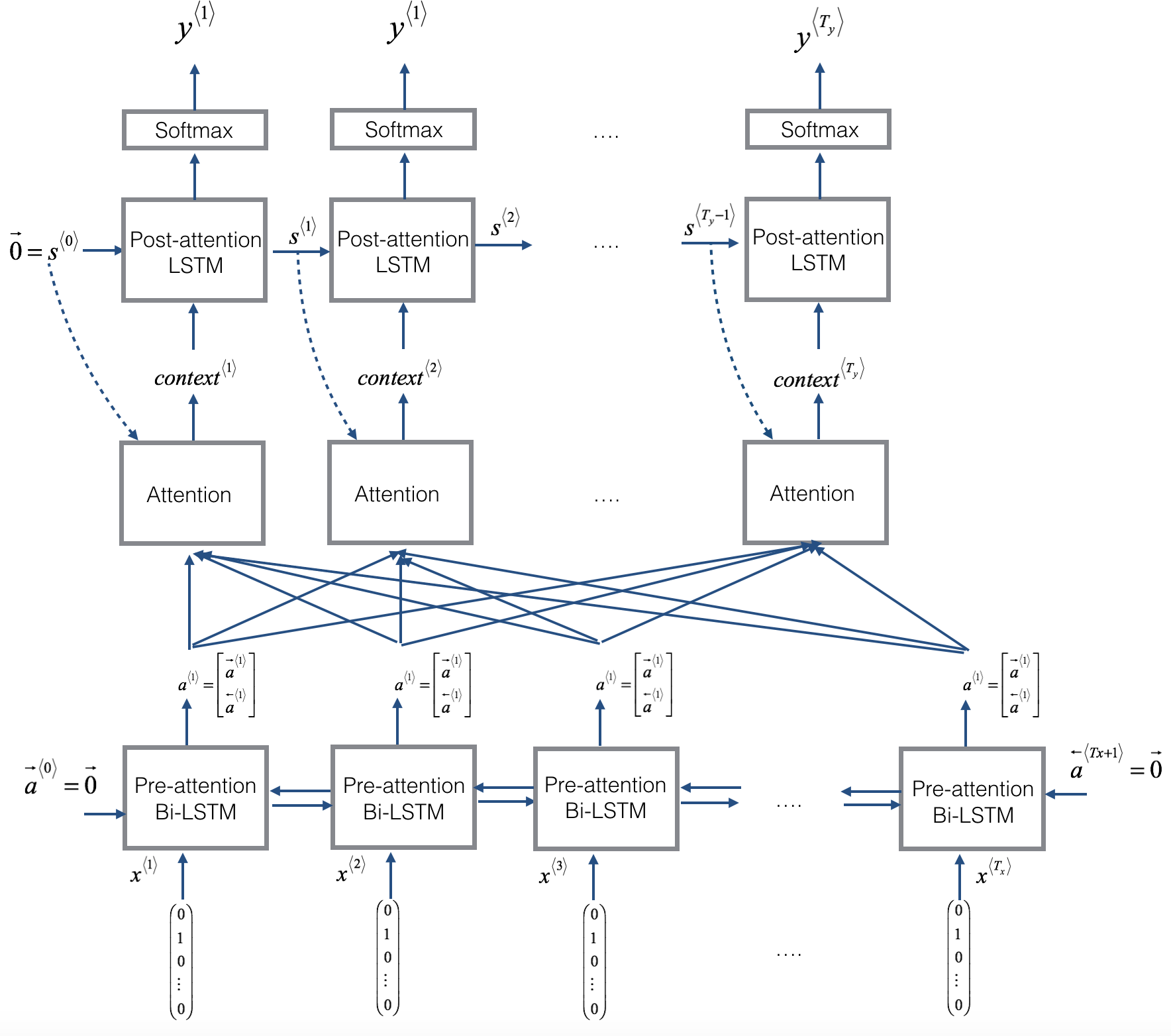
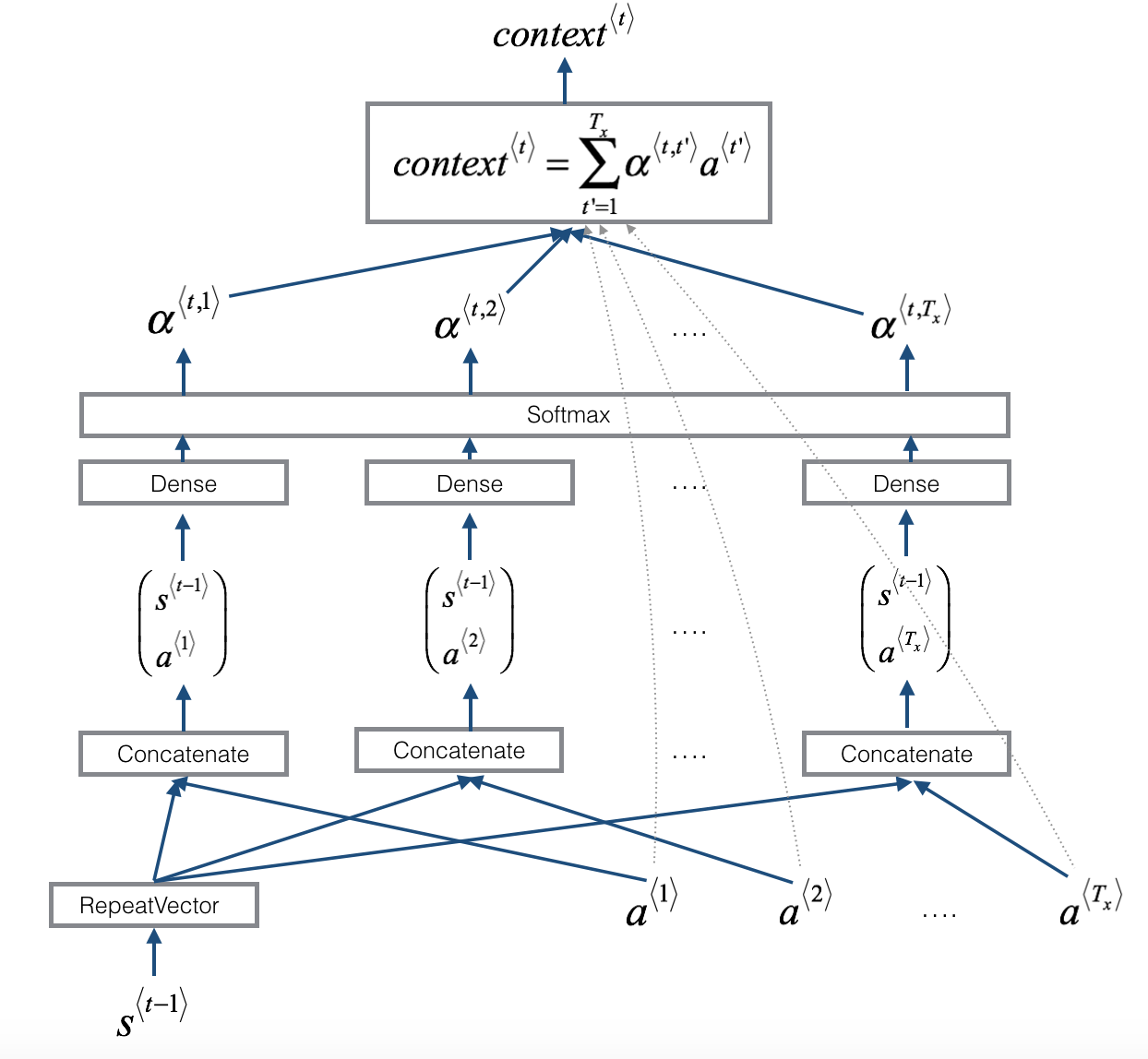
A small NN is trained to produce an attention vector, alpha. At each step t in the output, alpha <t, t‘> gives a weight for each activation a<t‘> in the input specifying the degree of attention on the input words while producing that output word.
Date formatting
People format dates in a ridiculous variety of ways. The first exercise is to build a translation-with-attention model to reformat dates to the standard way, like so.
| human readable | standardized |
|---|---|
| 3 May 1979 | 1979-05-03 |
| 5 April 09 | 2009-05-05 |
| 21th of August 2016 | 2016-08-21 |
| Tue 10 Jul 2007 | 2007-07-10 |
| Saturday May 9 2018 | 2018-05-09 |
| March 3 2001 | 2001-03-03 |
| March 3rd 2001 | 2001-03-03 |
| 1 March 2001 | 2001-03-01 |
Speech recognition
Humans, at least those with healthy young ears, can hear frequencies between 20 and 20,000 hertz. Interpretting those frequencies into words in the presence of background noise is one of those mysterious perceptual tasks that human brains and NN’s seem to do well.
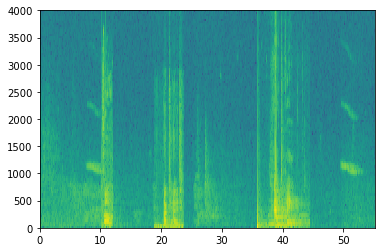
The spectrogram shows three spoken words, “phone”, “activate” in a male voice, “activate” in a female voice. Our goal is to detect the word “activate” as if we wanted to wake-up a device similar to an Alexa. There’s a cool background-noise artifact with three clear harmonics that descend in pitch right before the first word and repeating after the last. It sounds like bird chirp.
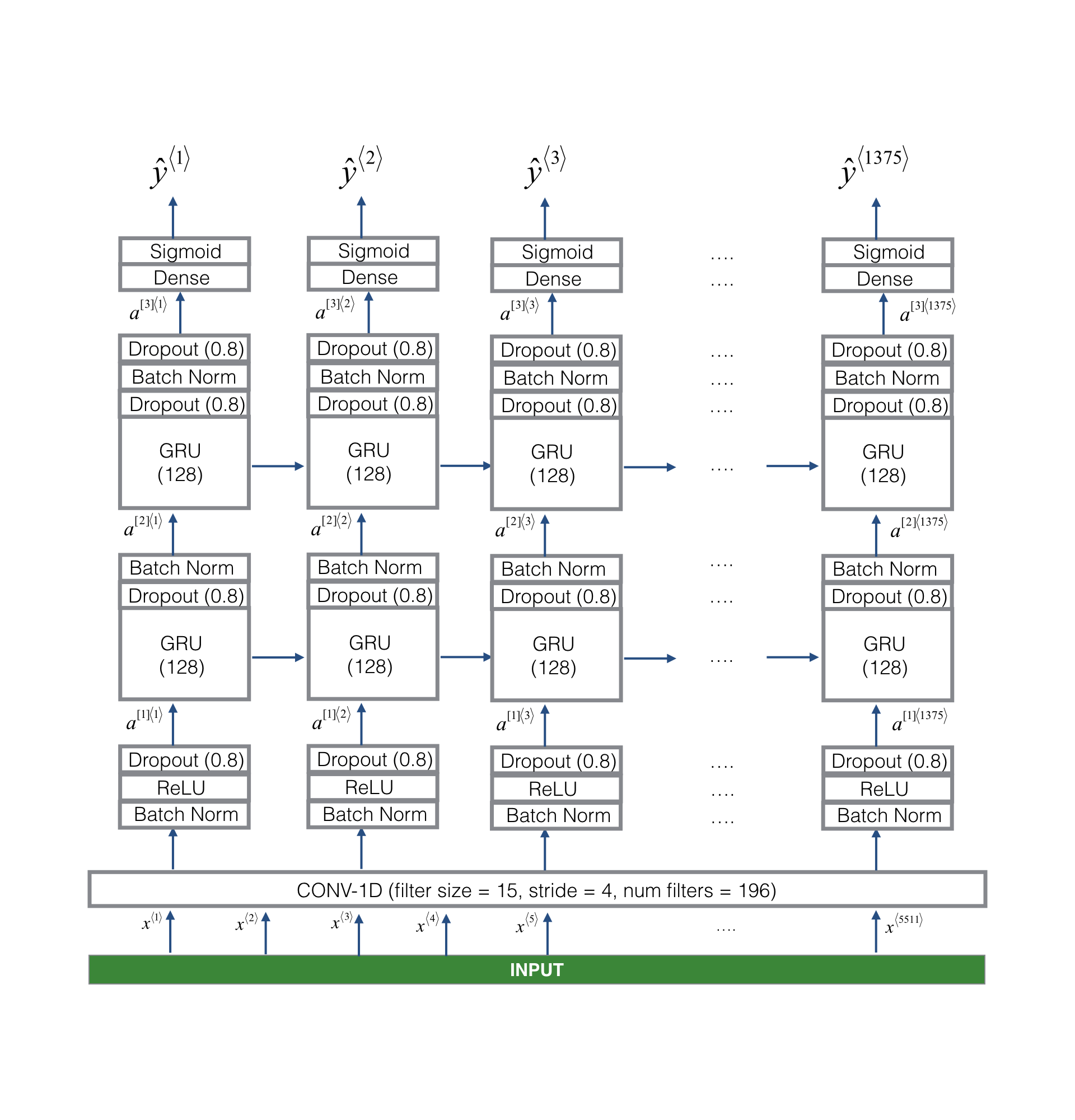
It would be interesting to know more about the role of the 1D convolutional layer compared to attention.
Done!
And, just like that… we’re done! Thanks, Andrew Ng.