Parallelizing HTTP requests
One of the gotchas when doing microservices is joining across services. Since the database can no longer do that work for you, programmers typically build intermediate endpoints to gather together data and serve it out to clients in a convenient form. But, making too many requests in an intermediate service risks running into time-outs.
One solution is to do some of that work in parallel. Working in Python (strictly in CPython) presents the challenge of the GIL, the global interpreter lock. That means we only get parallelism for things that don’t involve executing interpreted Python code, mainly IO.
So how much does it help is to parallelize those HTTP service calls? I had an endpoint to implement and wondered whether parallelizing was worth the trouble, so I did a little experiment.
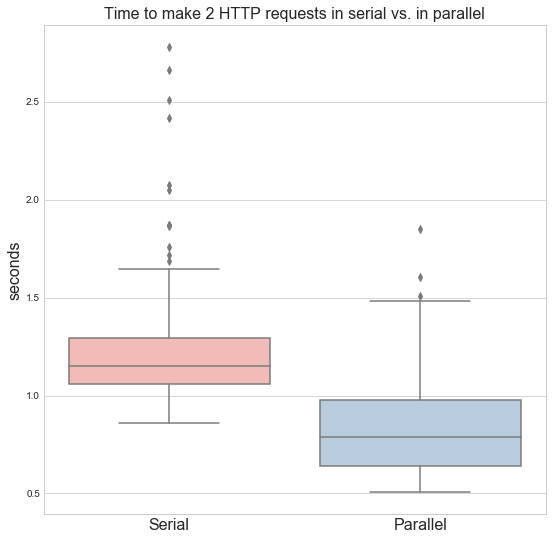
The median time to complete the two calls in serial was a pokey 1.15 seconds, while in parallel they took a median of 0.79 seconds. That’s about 30% quicker. Not bad. It’s not double due to the interpreter’s single threaded nature and because spawning threads adds some overhead.
We could also look at the timings as distributions.
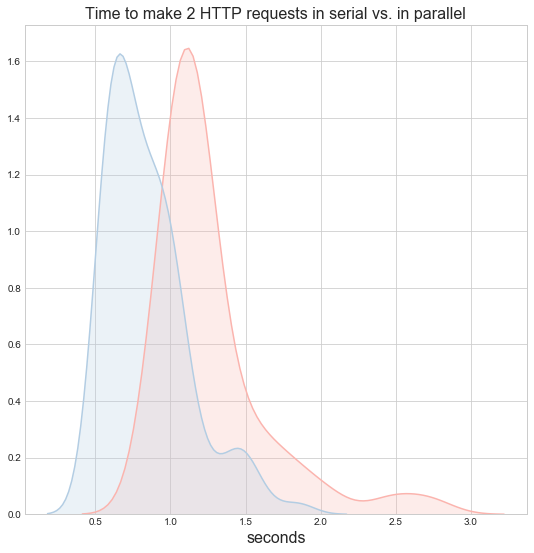
That’s on the border of what I’d consider worthwhile unless we’re doing something particularly performance sensitive. Threading is harder to reason about and debug. Even with the speedup, these calls are on the slow side, so perhaps there are easy gains to be had from in speeding up the downstream services. But, very likely, if we start making more than two secondary calls, the benefits of parallelizing start to add up.