TensorFlow, deep learning and recurrent neural networks

The excellent folks of GDGSeattle and Seattle-DAML put on a couple of workshops on deep learning and Google’s TensorFlow package featuring talks and codelabs by Martin Görner.
The materials from these sessions are great resources.
Slides
Intro slides by Margaret Maynard-Reid:
Parts 1-5 of TensorFlow and Deep Learning without a PhD:
- TensorFlow and Deep Learning without a PhD
- Recurrent Neural Networks or Recurrent Neural Networks
- Convolutional Neural Nets
- Modern RNN Architectures
- Deep Reinforcement Learning
Codelab
Video
Martin’s talks seems to exist in multiple versions on YouTube.
- Tensorflow and deep learning without a PhD
- Tensorflow, deep learning and modern RNN architectures, without a PhD
- Tensorflow, deep learning and modern convolutional neural nets, without a PhD
- TensorFlow and Deep Learning without a PhD, Part 1
- TensorFlow and Deep Learning without a PhD, Part 2
Papers
- Teaching Machines to Read and Comprehend
- A Neural Conversational Model
- Neural Machine Translation by Jointly Learning to Align and Translate
- Neural Turing Machines
Hallucinated Shakespeare
Martin has a handful of tutorials on GitHub including the amazing RNN-Shakespeare.

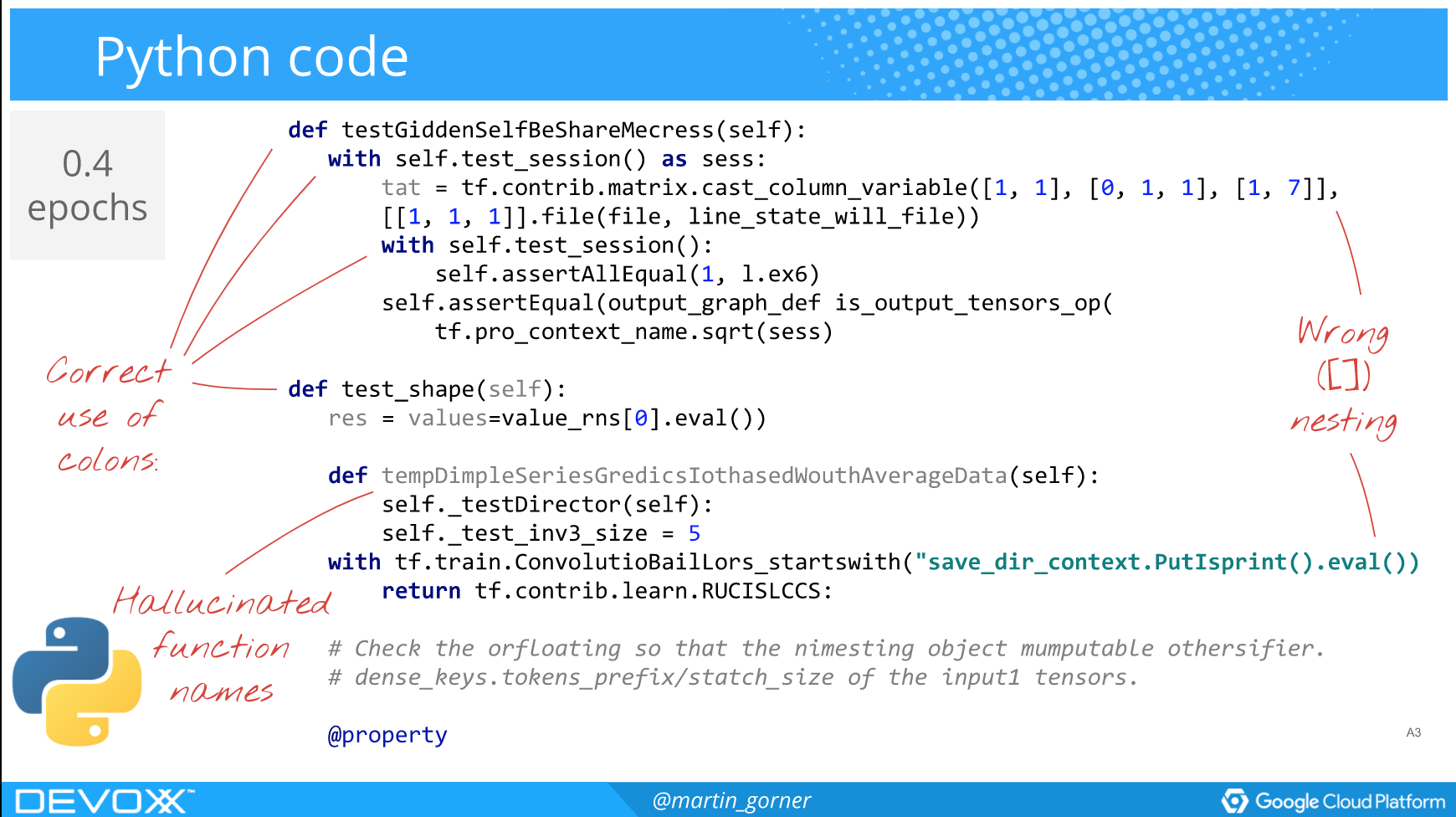
Hallucinated Python
Applied to the Python code of TensorFlow itself, after 0.4 epochs of training it looks like this:
…and after 12 epochs of training? Looks good to me. Ship it!
